#06 | Locating & Filtering the pandas.DataFrame
Learn everything about filtering specific parts of the DataFrame based on conditions.


Possibilities
Sometimes, we want to select specific parts of the DataFrame to highlight some data points.
In this case, we refer to the topic as locating & filtering.
For example, let's load the dataset of cars:
import seaborn as sns
df_mpg = sns.load_dataset('mpg', index_col='name').drop(columns=['cylinders', 'model_year', 'origin'])
df_mpg
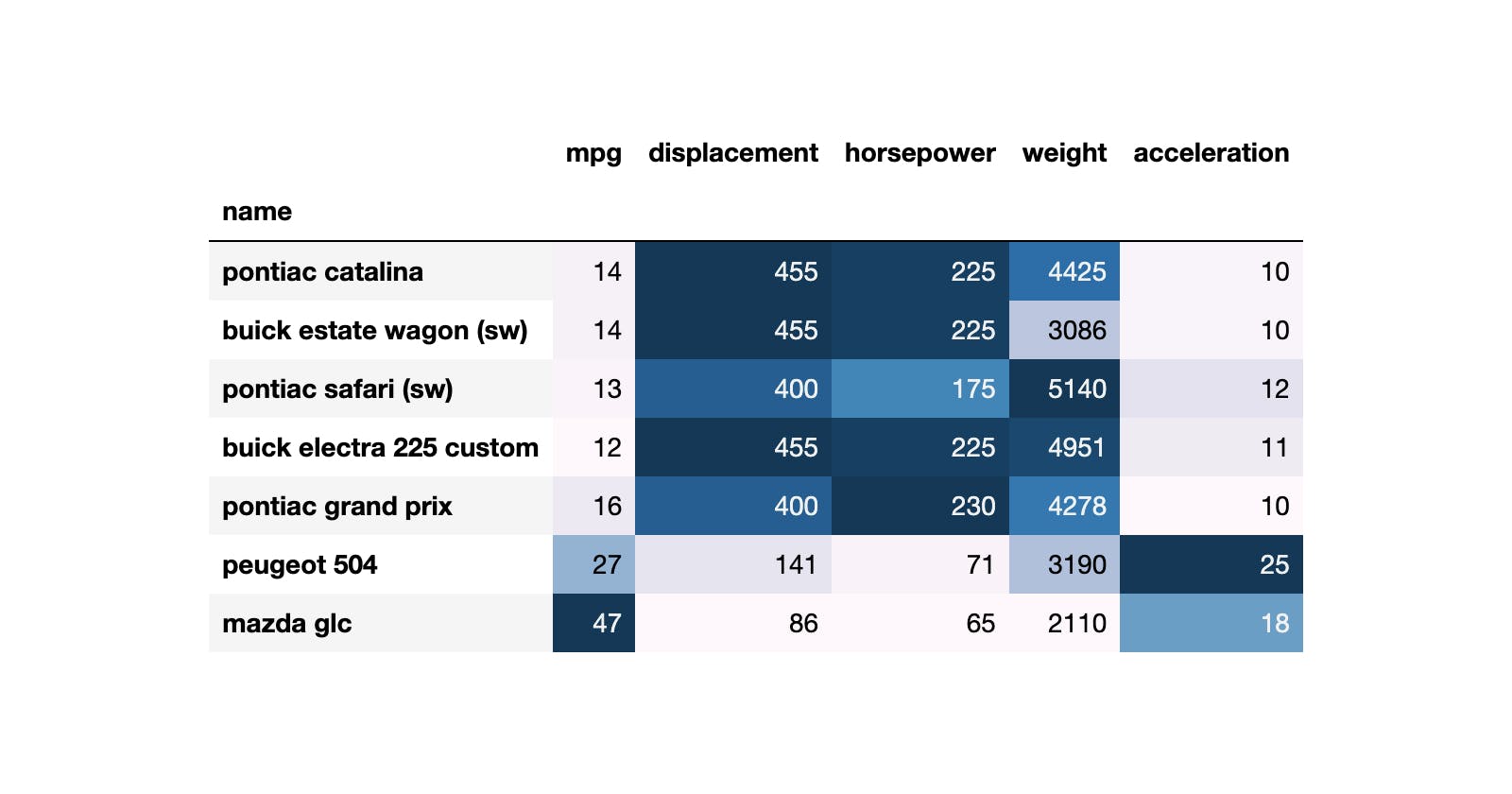
To filter the best cars in each statistics/column.
First, we calculate the maximum values in each column:
df_mpg.max()
mpg 46.6 displacement 455.0 horsepower 230.0 weight 5140.0 acceleration 24.8 dtype: float64
Then, we create a mask (array with True/False) to capture the rows where we have the cars with maximum values:
mask_max = (df_mpg == df_mpg.max()).sum(axis=1) > 0
mask_max
name chevrolet chevelle malibu False buick skylark 320 False ...
ford ranger False chevy s-10 False Length: 398, dtype: bool
Select the rows where the mask is True:
df_mpg_max = df_mpg[mask_max].copy()
df_mpg_max
And add some styling:
df_mpg_max.style.format('{:.0f}').background_gradient()
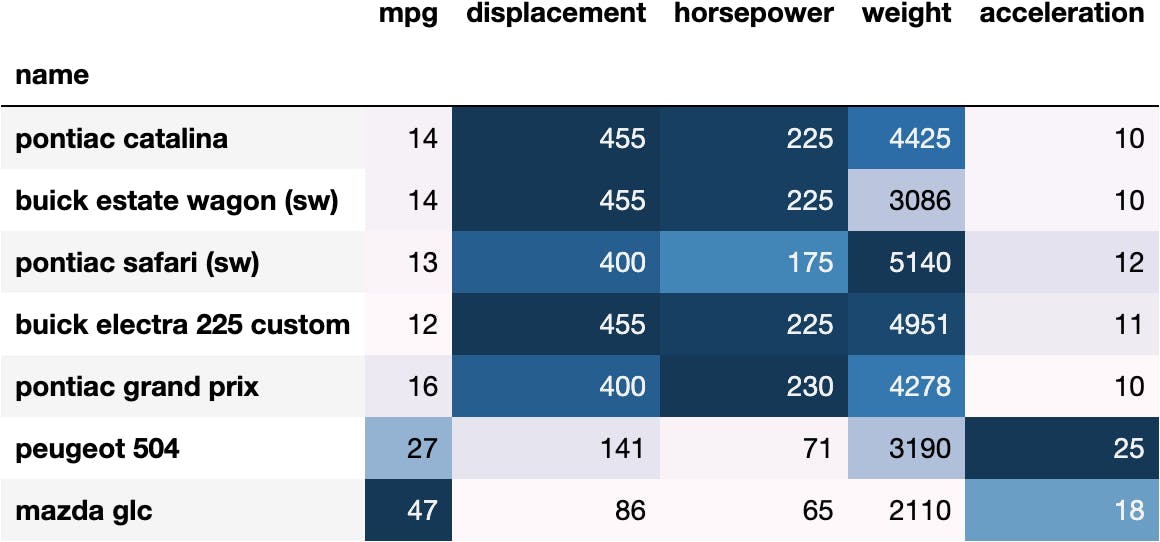
To understand the reasoning behind the previous example, read the rest of the article, where we explain the logic from the most basic example to locating data based on the index.
Any Object
By now, we should know the difference between the brackets [] and the parenthesis ().
We use brackets to select parts of an object. For example, let's create a list of days:
list_days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
And select the second element:
list_days[1]
'Tuesday'
Or the last element:
list_days[-1]
'Sunday'
Until the third element (included):
list_days[:3]
['Monday', 'Tuesday', 'Wednesday']
Nevertheless, the list is a simple element of Python. To get more functionalities, we use the Series object from pandas library.
Series
Let's create a Series to store the Apple Stock Return on Investment (ROI) by quarters:
import pandas as pd
sr_apple = pd.Series(
data=[59.02, 63.57, 66.93, 69.05],
index=['1Q', '2Q', '3Q', '4Q']
)
sr_apple
1Q 59.02 2Q 63.57 3Q 66.93 4Q 69.05 dtype: float64
iloc (integer-location) property
We use .iloc[] to select parts of the object based on the integer position of the element.
For example, let's select the first quarter ROI:
sr_apple.iloc[0]
59.02
Now, let's select the first and third quarters:
To select more than one object, we need to use double brackets [[]]:
sr_apple.iloc[[0,2,3]]
1Q 59.02 3Q 66.93 4Q 69.05 dtype: float64
Could we have accessed with the name 1Q?
sr_apple.iloc['Q1']
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [99], in <cell line: 1>() ----> 1 sr_apple.iloc['Q1']
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexing.py:967, in _LocationIndexer.getitem(self, key) 964 axis = self.axis or 0 966 maybe_callable = com.apply_if_callable(key, self.obj) --> 967 return self._getitem_axis(maybe_callable, axis=axis)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexing.py:1517, in _iLocIndexer._getitem_axis(self, key, axis) 1515 key = item_from_zerodim(key) 1516 if not is_integer(key): -> 1517 raise TypeError("Cannot index by location index with a non-integer key") 1519 # validate the location 1520 self._validate_integer(key, axis)
TypeError: Cannot index by location index with a non-integer key
The iloc property only works in integers (the position of the subelements we want).
To select the elements by their label/name, we need to use the loc property:
loc (location) property
We select parts of an object with the .loc[] instance based on the label/name of the index:
sr_apple.loc['1Q']
59.02
sr_apple.loc[['1Q', '3Q', '4Q']]
1Q 59.02 3Q 66.93 4Q 69.05 dtype: float64
If we would like to access by the position, we'd get an error:
sr_apple.loc[0]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexes/base.py:3621, in Index.get_loc(self, key, method, tolerance) 3620 try: -> 3621 return self._engine.get_loc(casted_key) 3622 except KeyError as err:
File ~/miniforge3/lib/python3.9/site-packages/pandas/_libs/index.pyx:136, in pandas._libs.index.IndexEngine.get_loc()
File ~/miniforge3/lib/python3.9/site-packages/pandas/_libs/index.pyx:163, in pandas._libs.index.IndexEngine.get_loc()
File pandas/_libs/hashtable_class_helper.pxi:5198, in pandas._libs.hashtable.PyObjectHashTable.get_item()
File pandas/_libs/hashtable_class_helper.pxi:5206, in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 0
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
Input In [102], in <cell line: 1>() ----> 1 sr_apple.loc[0]
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexing.py:967, in _LocationIndexer.getitem(self, key) 964 axis = self.axis or 0 966 maybe_callable = com.apply_if_callable(key, self.obj) --> 967 return self._getitem_axis(maybe_callable, axis=axis)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexing.py:1202, in _LocIndexer._getitem_axis(self, key, axis) 1200 # fall thru to straight lookup 1201 self._validate_key(key, axis) -> 1202 return self._get_label(key, axis=axis)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexing.py:1153, in _LocIndexer._get_label(self, label, axis) 1151 def _get_label(self, label, axis: int): 1152 # GH#5667 this will fail if the label is not present in the axis. -> 1153 return self.obj.xs(label, axis=axis)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/generic.py:3864, in NDFrame.xs(self, key, axis, level, drop_level) 3862 new_index = index[loc] 3863 else: -> 3864 loc = index.get_loc(key) 3866 if isinstance(loc, np.ndarray): 3867 if loc.dtype == np.bool_:
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexes/base.py:3623, in Index.get_loc(self, key, method, tolerance) 3621 return self._engine.get_loc(casted_key) 3622 except KeyError as err: -> 3623 raise KeyError(key) from err 3624 except TypeError: 3625 # If we have a listlike key, _check_indexing_error will raise 3626 # InvalidIndexError. Otherwise we fall through and re-raise 3627 # the TypeError. 3628 self._check_indexing_error(key)
KeyError: 0
It results in KeyError because we don't have any Key in the index to be 0:
sr_apple
1Q 59.02 2Q 63.57 3Q 66.93 4Q 69.05 dtype: float64
We have:
sr_apple.keys()
Index(['1Q', '2Q', '3Q', '4Q'], dtype='object')
The loc property only works with the labels, not the position.
Masking with boolean objects
Now we'd like to select parts based on a condition. For example, let's show the quarters we had a Return on Investment (ROI) above 60.
First, we create a boolean object based on the stated condition:
sr_apple
1Q 59.02 2Q 63.57 3Q 66.93 4Q 69.05 dtype: float64
sr_apple > 60
1Q False 2Q True 3Q True 4Q True dtype: bool
mask_60 = sr_apple > 60
Now we pass the previous object to the .loc property:
sr_apple.loc[mask_60]
2Q 63.57 3Q 66.93 4Q 69.05 dtype: float64
And here, we have the data for which the ROI is higher than 60.
Just the brackets []
sr_apple
1Q 59.02 2Q 63.57 3Q 66.93 4Q 69.05 dtype: float64
We could also access the data by only using the brackets, without the ~.iloc~ property:
sr_apple['1Q']
59.02
And also, the position:
sr_apple[0]
59.02
And the mask:
sr_apple[mask_60]
2Q 63.57 3Q 66.93 4Q 69.05 dtype: float64
So far, we have played with 1-Dimensional objects. Now it's time to level up and play with 2-Dimensional objects, like the DataFrame.
DataFrame
Let's play with a dataset of cars:
import seaborn as sns
df_mpg = sns.load_dataset(name='mpg', index_col='name')
df_mpg
iloc (integer-location) property
We can select the second row:
df_mpg.iloc[2]
mpg 18.0 cylinders 8 displacement 318.0 horsepower 150.0 weight 3436 acceleration 11.0 model_year 70 origin usa Name: plymouth satellite, dtype: object
And keep the DataFrame style if we use double brackets [[]]:
df_mpg.iloc[[2]]

We can also slice (a term used for filtering as well) consecutive elements of the DataFrame with the colon :.
For example, let's select the first 4 rows:
df_mpg.iloc[:4]
Instead of:
df_mpg.iloc[[0,1,2,3]]
We can also select the columns we want.
For example, let's select the first 3 columns:
df_mpg.iloc[:4, :3]
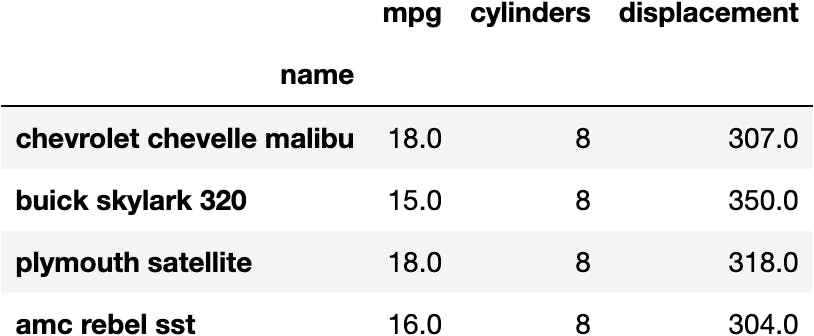
Learn how to become an independent Data Analyist programmer who knows how to extract meaningful insights from Data Visualizations.
Or the rest of the columns from the 3rd position (not included):
df_mpg.iloc[:4, 3:]
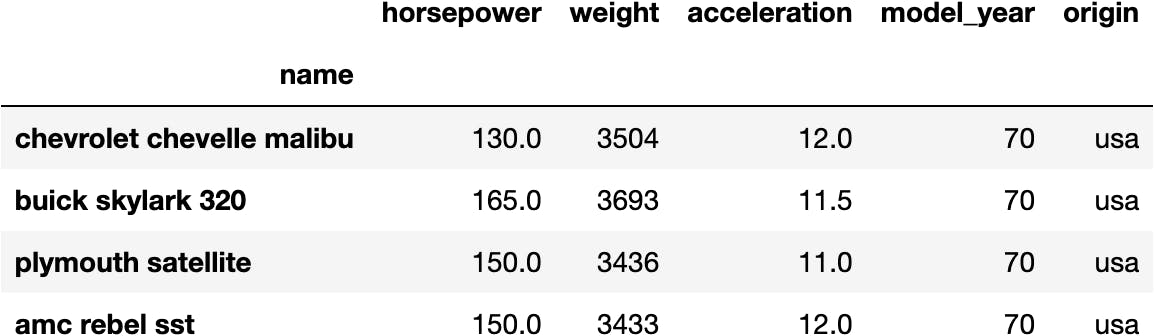
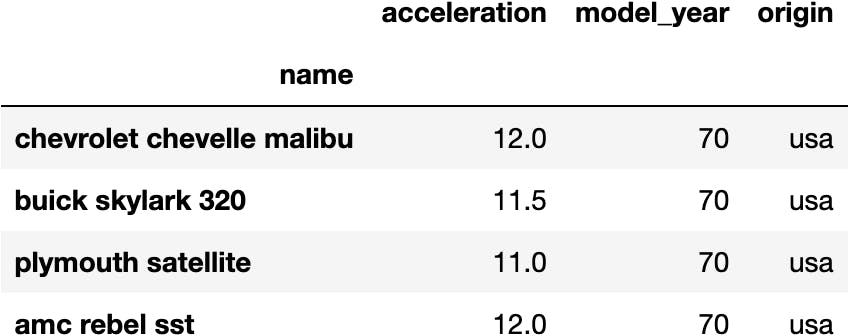
Or the last 3 columns by using the -:
df_mpg.iloc[:4, -3:]
loc (location) property
We can also select parts of the DataFrame based on the index and column labels (2-Dimensions):
df_mpg.loc[['ford torino', 'fiat 124 sport coupe'], ['origin', 'model_year', 'cylinders']]
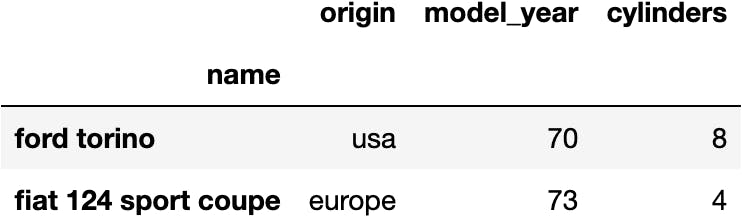
df_mpg.loc[:'fiat 124 sport coupe', :'cylinders']
Masking with boolean objects
Single Condition
Out of all the cars:
df_mpg.index
Index(['chevrolet chevelle malibu', 'buick skylark 320', 'plymouth satellite', 'amc rebel sst', 'ford torino', 'ford galaxie 500', 'chevrolet impala', 'plymouth fury iii', 'pontiac catalina', 'amc ambassador dpl', ... 'chrysler lebaron medallion', 'ford granada l', 'toyota celica gt', 'dodge charger 2.2', 'chevrolet camaro', 'ford mustang gl', 'vw pickup', 'dodge rampage', 'ford ranger', 'chevy s-10'], dtype='object', name='name', length=398)
We could select all the fiat cars if we had a boolean array based on this condition:
mask_fiat = df_mpg.index.str.contains('fiat')
mask_fiat
array([False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, True, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False])
We can observe a few Trues where we find some Fiats.
Let's filter them and show all the columns with the ::
df_mpg.loc[mask_fiat, :]
Although we could have omitted the ::
df_mpg.loc[mask_fiat]
Multiple Conditions
Both Conditions &
Just the fiats whose horsepower is above 80:
mask_hp = df_mpg.horsepower > 80
mask_hp
name chevrolet chevelle malibu True buick skylark 320 True ...
ford ranger False chevy s-10 True Name: horsepower, Length: 398, dtype: bool
df_mpg.loc[mask_hp & mask_fiat, :]

Any Condition |
We could also select all fiats OR cars whose horsepower is above 80:
df_mpg.loc[mask_hp | mask_fiat, :]
Just the brackets []
We can select the columns by their labels:
df_mpg['acceleration']
name chevrolet chevelle malibu 12.0 buick skylark 320 11.5 ... ford ranger 18.6 chevy s-10 19.4 Name: acceleration, Length: 398, dtype: float64
df_mpg[['acceleration', 'origin', 'model_year']]
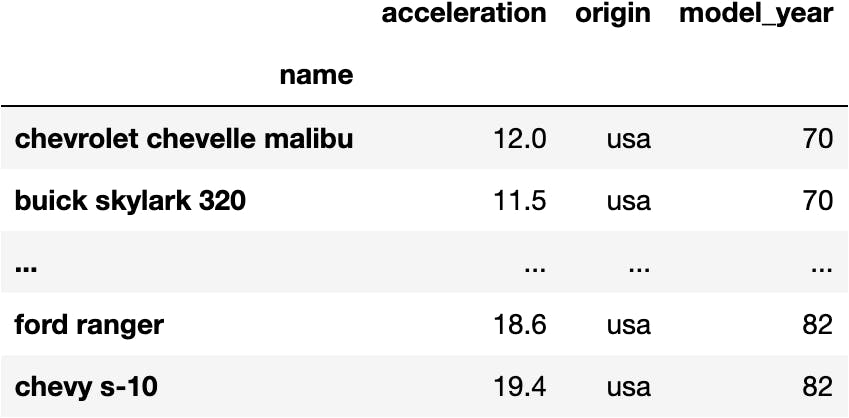
But we can't select the rows by the index labels:
df_mpg['amc rebel sst']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexes/base.py:3621, in Index.get_loc(self, key, method, tolerance) 3620 try: -> 3621 return self._engine.get_loc(casted_key) 3622 except KeyError as err:
...
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexes/base.py:3623, in Index.get_loc(self, key, method, tolerance) 3621 return self._engine.get_loc(casted_key) 3622 except KeyError as err: -> 3623 raise KeyError(key) from err 3624 except TypeError: 3625 # If we have a listlike key, _check_indexing_error will raise 3626 # InvalidIndexError. Otherwise we fall through and re-raise 3627 # the TypeError. 3628 self._check_indexing_error(key)
KeyError: 'amc rebel sst'
Unless we use the colon ::
df_mpg[:'amc rebel sst']
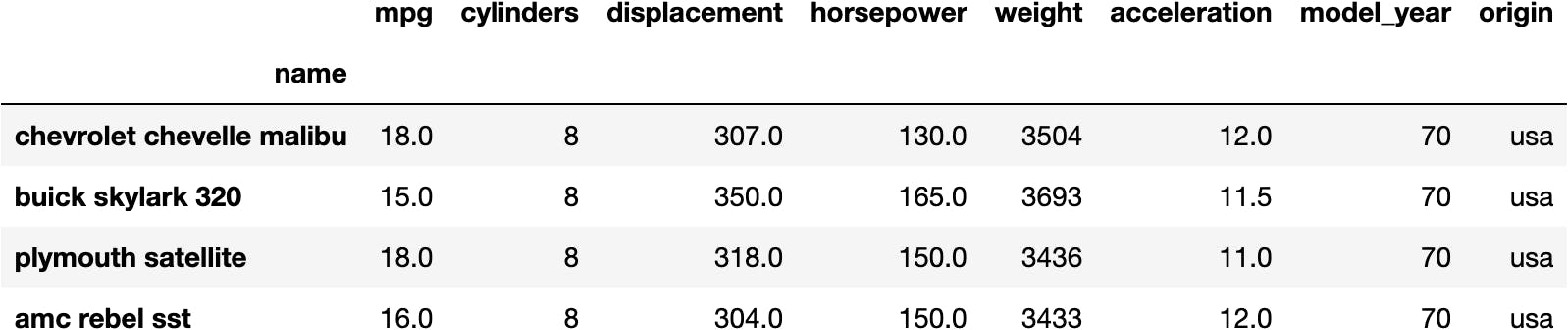
df_mpg['buick skylark 320':'amc rebel sst']

We can also select the rows by position:
df_mpg[:4]
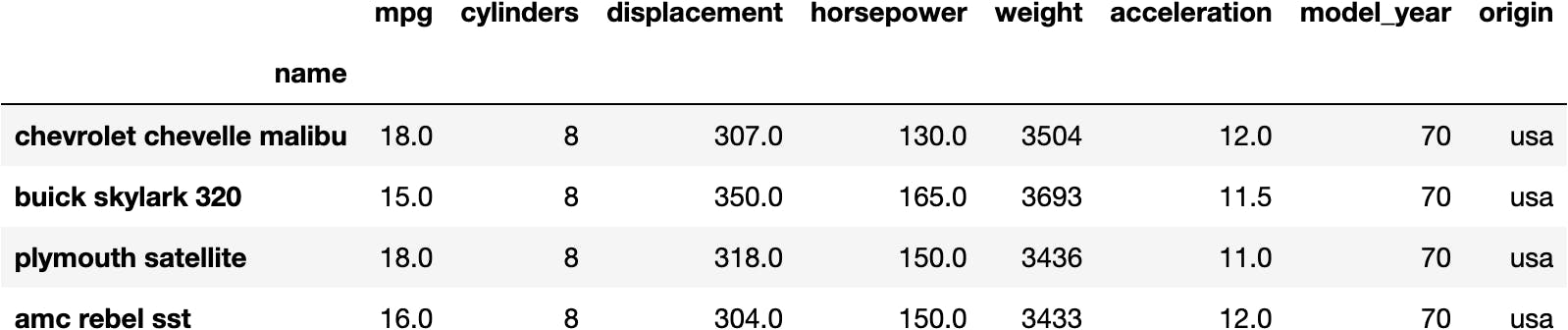
But we can't select both rows and columns (2-Dimensions):
df_mpg[:4,:3]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexes/base.py:3621, in Index.get_loc(self, key, method, tolerance) 3620 try: -> 3621 return self._engine.get_loc(casted_key) 3622 except KeyError as err:
...
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexes/base.py:5637, in Index._check_indexing_error(self, key) 5633 def _check_indexing_error(self, key): 5634 if not is_scalar(key): 5635 # if key is not a scalar, directly raise an error (the code below 5636 # would convert to numpy arrays and raise later any way) - GH29926 -> 5637 raise InvalidIndexError(key)
InvalidIndexError: (slice(None, 4, None), slice(None, 3, None))
Unless we specify the columns we want in extra brackets:
df_mpg[:4]['acceleration']
name chevrolet chevelle malibu 12.0 buick skylark 320 11.5 plymouth satellite 11.0 amc rebel sst 12.0 Name: acceleration, dtype: float64
df_mpg[:4][['acceleration']]

df_mpg[:4][['acceleration', 'origin']]

We can also select the rows given boolean-arrays (a.k.a. masks):
df_mpg[mask_fiat]
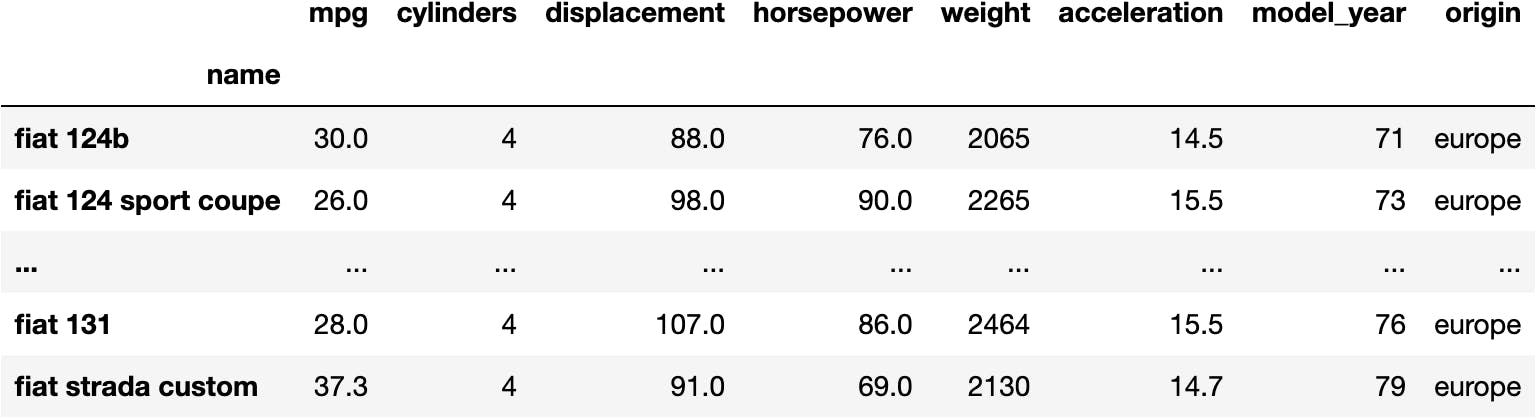
df_mpg[mask_fiat | mask_hp]
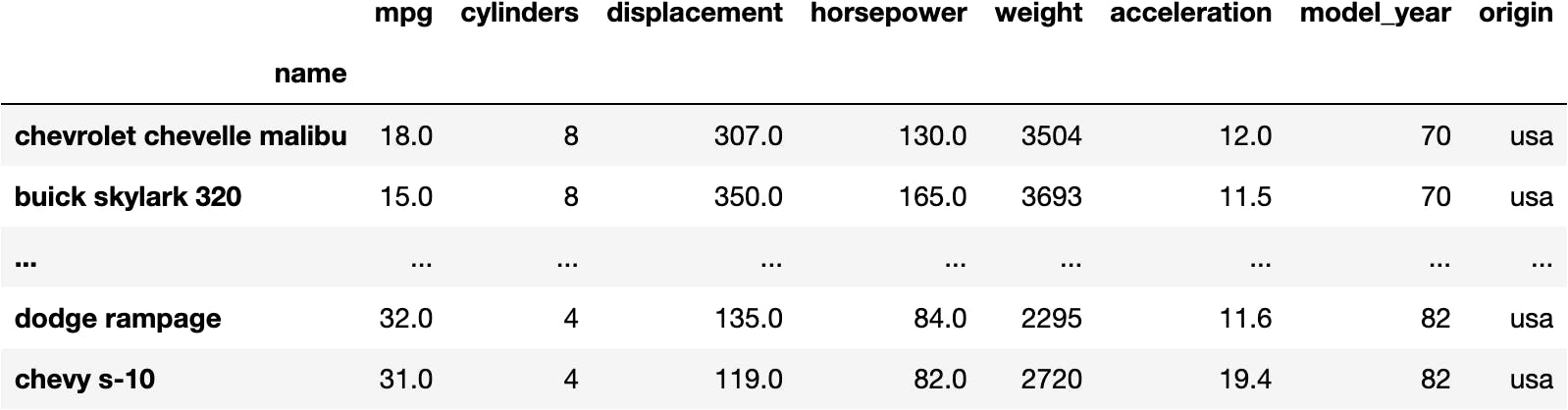
df_mpg[mask_fiat & mask_hp]

It doesn't mean that I cannot later select the columns that we want (programming is the art of everything, we just need to find a way):
df_mpg[mask_fiat & mask_hp]['mpg']
name fiat 124 sport coupe 26.0 fiat 131 28.0 Name: mpg, dtype: float64
df_mpg[mask_fiat & mask_hp][['mpg', 'origin', 'model_year']]

Everything may be a bit confusing, but we hope you get the main idea behind locating and masking:
Select the parts of an object with brackets
[]We can access it through
The label/name
locThe integer position
ilocMasks: boolean arrays based on conditions
Just the brackets
[]*
If the object has:
1-Dimension
object[:]2-Dimension
object[:,:]
*Carefully because it has many variations of use case, as we observed above
DataFrame MultiIndex
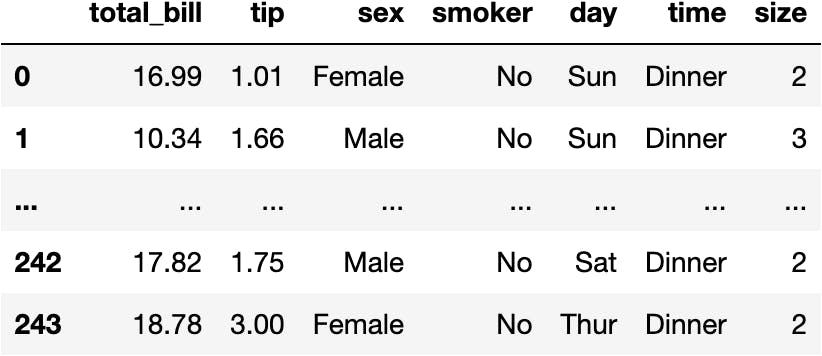
Let's load a dataset with various categorical columns since we summarise data based on categories, not numbers.
df_tips = sns.load_dataset(name='tips')
df_tips
Let's make a pivot table to summarise the information to obtain a Hierarchical* DataFrame.
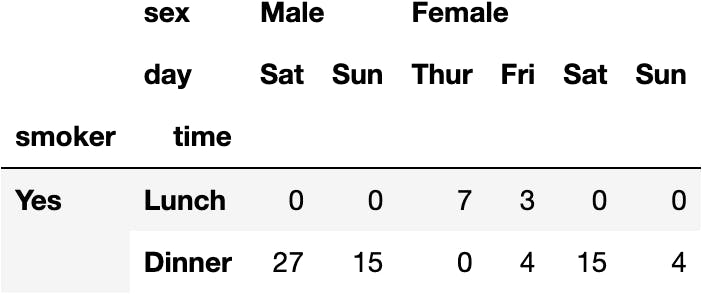
dfres = df_tips.pivot_table(index=['smoker', 'time'], columns='sex', aggfunc='size')
dfres
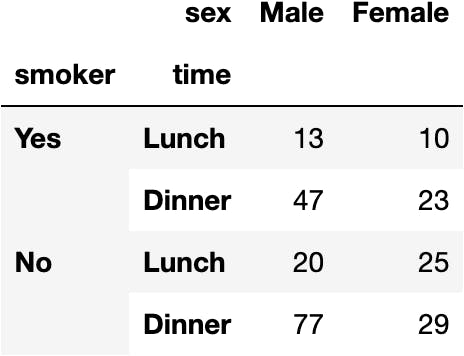
*A Hierarchical DataFrame (MultiIndex) contains two "columns" as an index. As we may observe below:
dfres.index
MultiIndex([('Yes', 'Lunch'), ('Yes', 'Dinner'), ( 'No', 'Lunch'), ( 'No', 'Dinner')], names=['smoker', 'time'])
First Index
Let's locate some parts of the Hierarchical DataFrame:
dfres
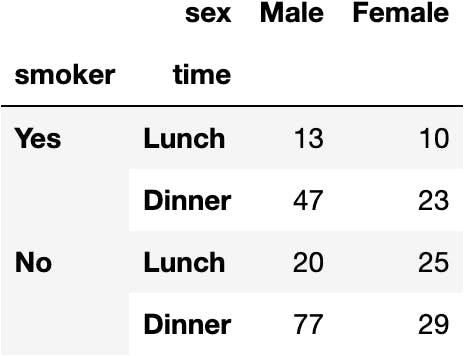
By using the .loc property:
dfres.loc['Yes', :]

dfres.loc['No', :]

Second Index
As we have multiple indexes [index1, index2, columns], we can select a part of the second index:
dfres.loc[:, 'Lunch', :]

dfres.loc[:, 'Dinner', :]

DataFrame MultiIndex & MultiColumns
Let's now play with a DataFrame that is both MultiIndex and MultiColumns:
dfres = df_tips.pivot_table(index=['smoker', 'time'], columns=['sex', 'day'], aggfunc='size')
dfres
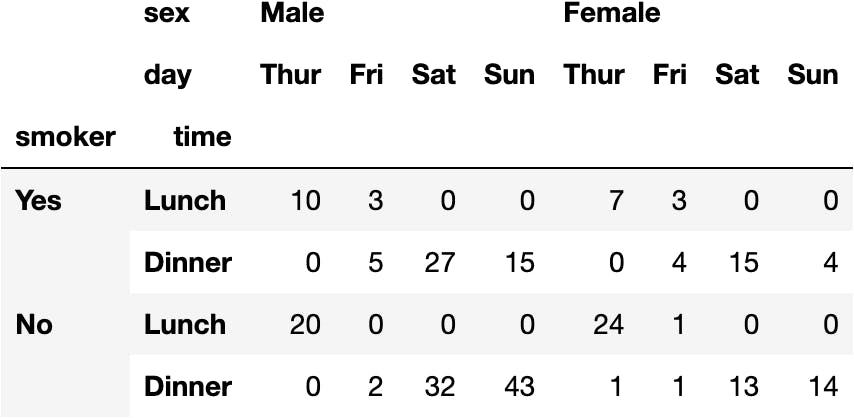
We may observe two levels in the columns above.
loc (location) property
First Index
We apply the same reasoning we used in the previous sections, [index1, index2, column1, column2].
dfres.loc['No', :, :, :]
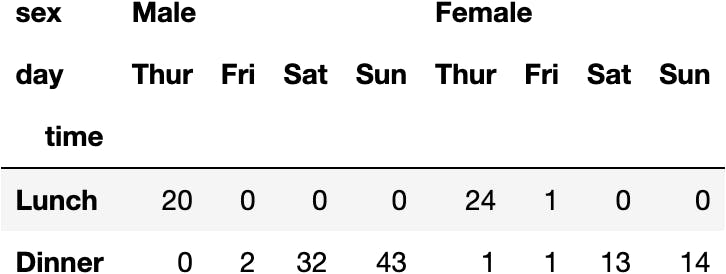
Although, we can make it shorter.
dfres.loc['No', :]
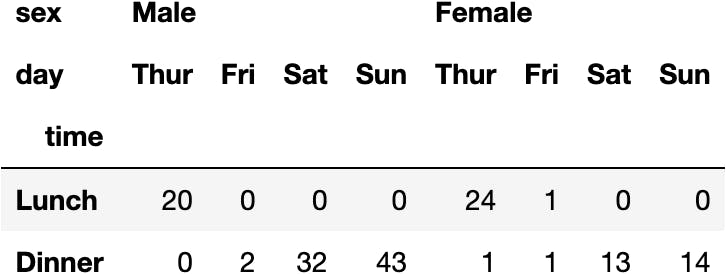
Second Index
The same applies to the second index:
dfres.loc[:,'Dinner', :, :]
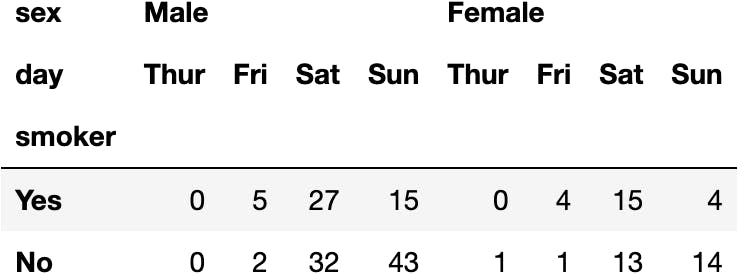
dfres.loc[:,'Dinner', :]
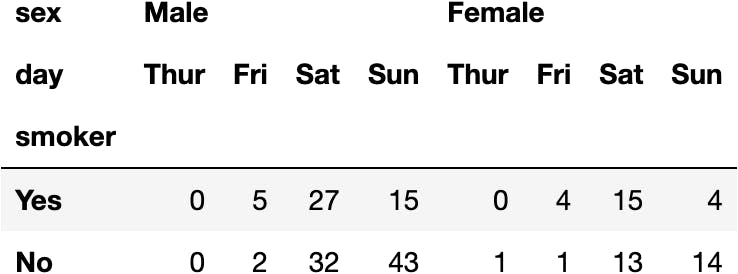
Second Index & Second Column
Let's try to get Dinners on Sundays:
dfres.loc[:, 'Dinner', :, 'Sun']
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Input In [158], in <cell line: 1>() ----> 1 dfres.loc[:, 'Dinner', :, 'Sun']
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexing.py:961, in _LocationIndexer.getitem(self, key) 959 if self._is_scalar_access(key): 960 return self.obj._get_value(*key, takeable=self._takeable) --> 961 return self._getitem_tuple(key) 962 else: 963 # we by definition only have the 0th axis 964 axis = self.axis or 0
...
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/indexes/frozen.py:70, in FrozenList.getitem(self, n) 68 if isinstance(n, slice): 69 return type(self)(super().getitem(n)) ---> 70 return super().getitem(n)
IndexError: list index out of range
To make it work, this time we need to create an intermediate object to separate rows and columns:
idx = pd.IndexSlice
dfres.loc[idx[:, 'Dinner'], idx[:, 'Sun']]

Second Index & First Column
dfres.loc[idx[:, 'Dinner'], idx['Male', :]]

Using the Slice
We can also use the slice() property:
dfres.loc[('Yes', slice(None)), (slice(None), 'Sun')]

dfres.loc['Yes', ('Female', slice(None))]
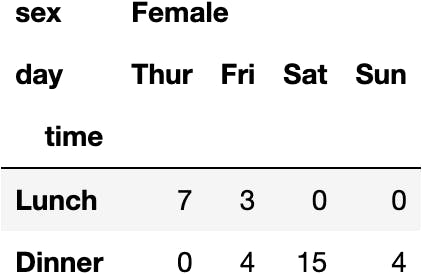
dfres.loc[(slice(None), 'Lunch'), 'Female']

dfres.loc[(slice(None), 'Lunch'), ('Female', slice(None))]

dfres.loc[idx[:, 'Dinner'], idx['Female', :]]

iloc (integer-location) property
dfres
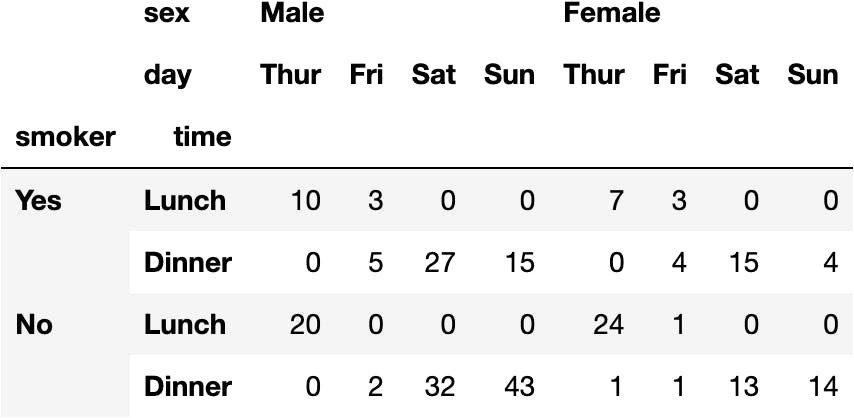
As always, we can select by the position of the values with the iloc property:
dfres.iloc[:2, :2]
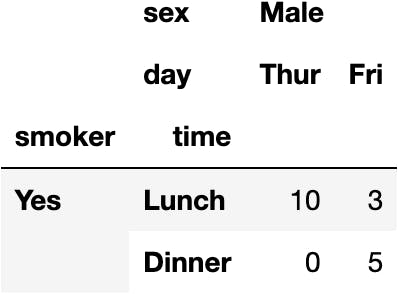
dfres.iloc[:2, 2:]
DataFrame with DateTimeIndex
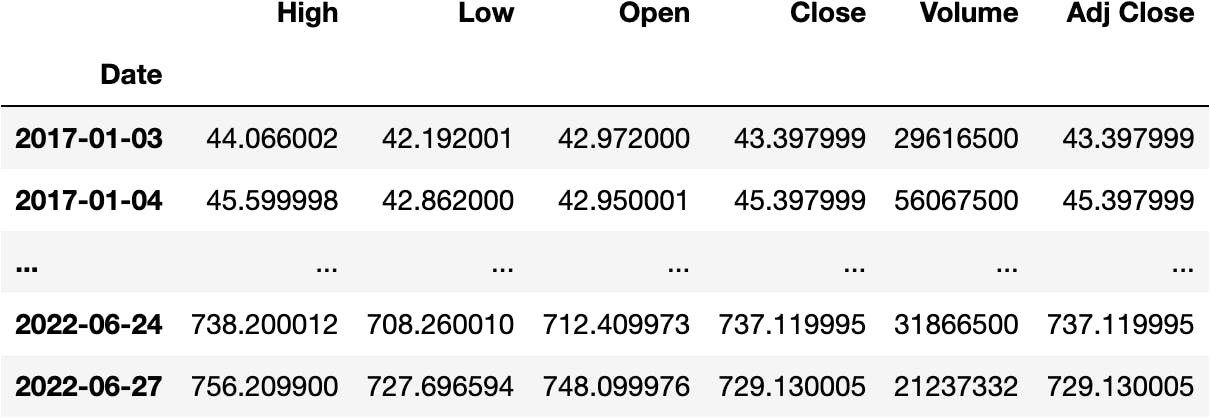
Now, we will use a DataFrame that has a DateTimeIndex:
df_tsla = pd.read_excel('tsla_stock.xlsx', index_col=0)
df_tsla
loc (location) property
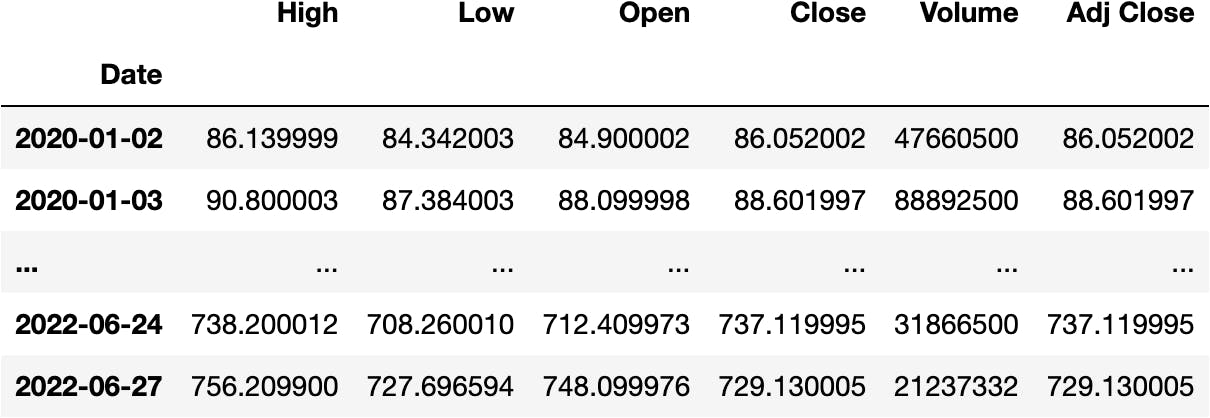
We can select parts of the DataFrame based on just one part of the DateTimeIndex. For example, we can select everything from the year 2020 and move forward:
df_tsla.loc['2020':]
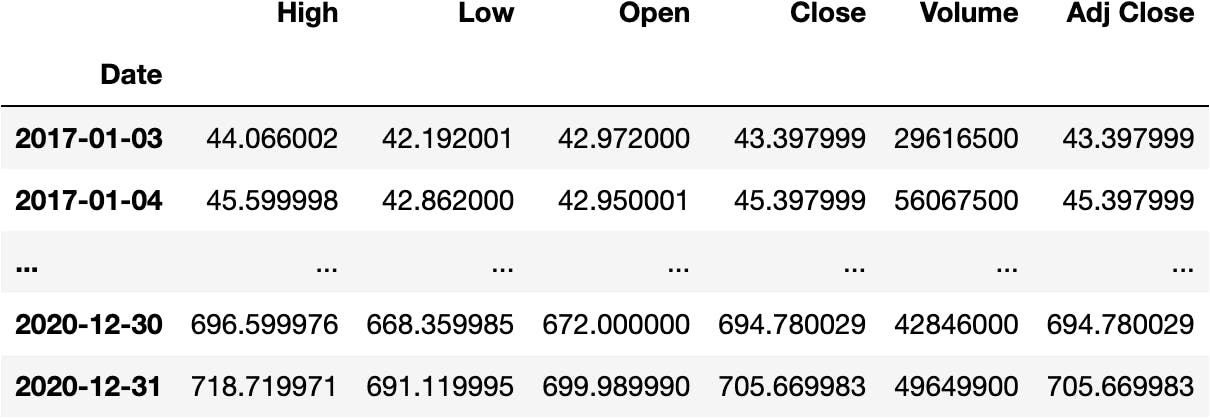
Until the last day of 2020:
df_tsla.loc[:'2020']
Between two years:
df_tsla.loc['2019':'2020']
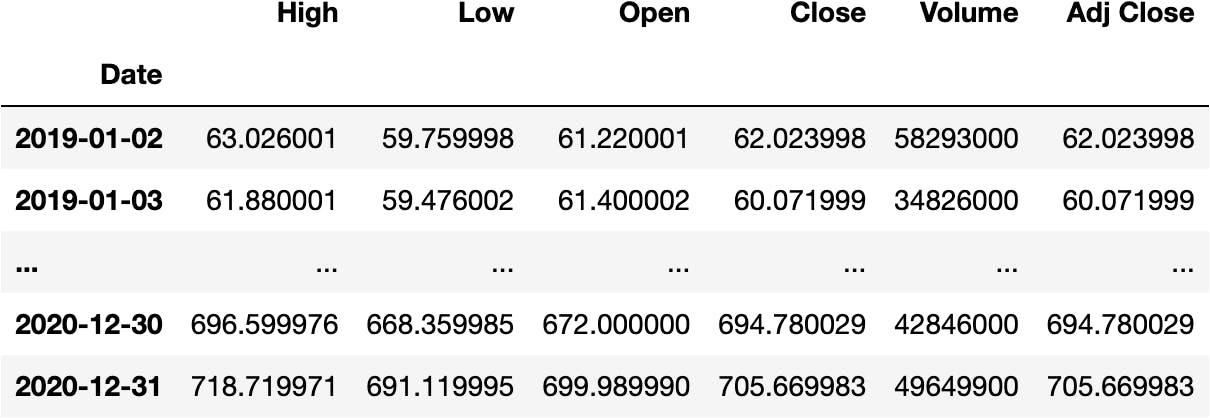
One complete year:
df_tsla.loc['2019']
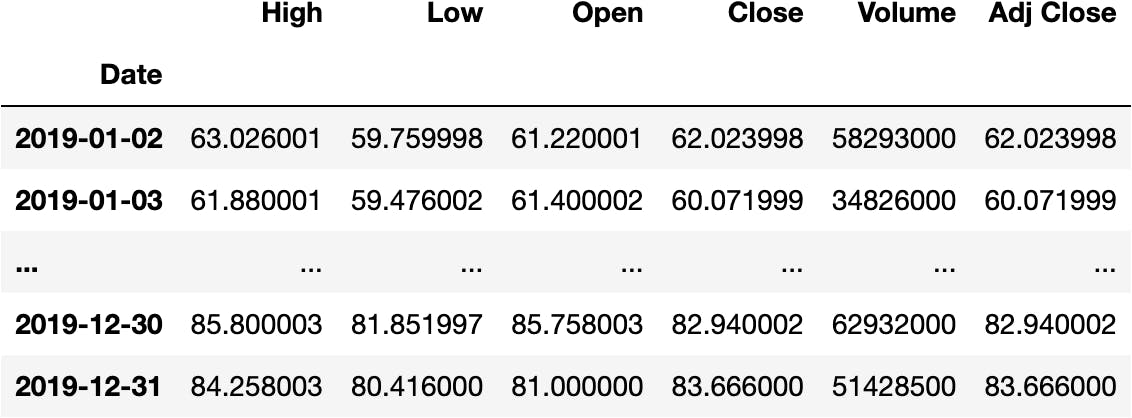
We can even select a specific year-month:
df_tsla.loc['2019-06']
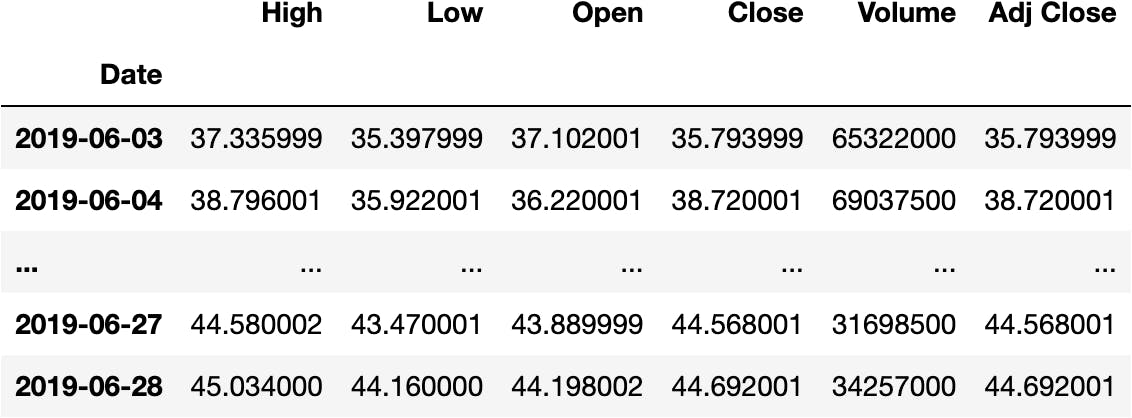
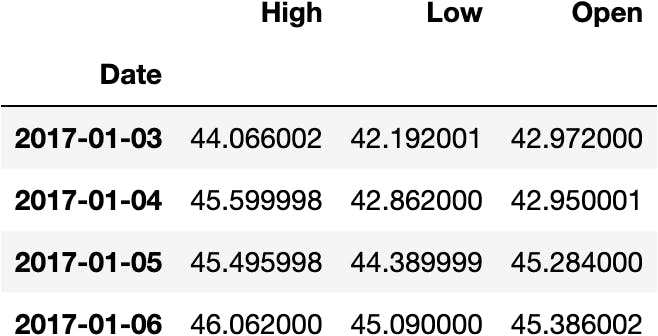
iloc (integer-location) property
Of course, we can also select parts of the DataFrame based on the position of the values with iloc:
df_tsla.iloc[:4, :3]
df_tsla.iloc[-4:, :3]